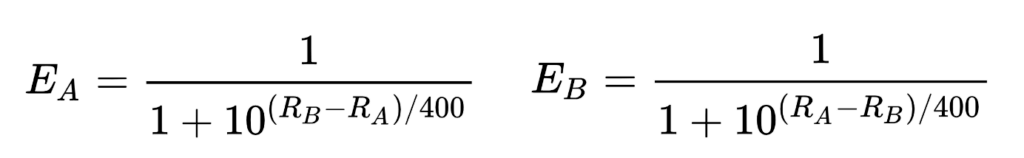What is the iGP-Rating?
iGP-Rating is a scoring system related to the value of each driver in iGPFun races. Its first version was developed in 2004, we are now reactivating it for league races.
The higher the rating the better results a driver obtained in the past.
A higher rating driver is expected to beat one with a lower rating, the more easily the larger the difference between the two ratings.
What does it represent?
iGP-Rating is based on the Elo system, developed for chess. It is the same concept used by the iRating but with slightly different calculations. The exact terms used in the iRating are not known.
These ratings are only affected by the final standings. They do not differentiate between the drivers laptimes, nor it can tell if drivers classify last because they crash by themselves or are innocent victims of a multi-car accident.
A Qualify-rating is used to evaluate the qualifying performance, which is more related to pure speed.
How does it work?
Let’s start with a formula and use an example later.
It its simplest form, the iGP-Rating for a driver A is calculated as follows:
GP1 = GP0 + W*V*(EA-RA)
– GP1 is the new rating after a race; GP0 is the old rating, before the race.
– W is a number that becomes smaller the more races a driver has run, allowing the rating to change less after many races. The idea is that initially the rating will not reflect the true value of a driver. Imagine an alien joining its first race: it would have a much lower rating than deserved. Letting the rating change a lot (rapidly) makes sense.
Conversely, after many races the rating should give a good indication of a racer value. Having it change a lot just because of a single, bad result, for instance due to a crash, would be less than ideal.
Note that this approach is opposite to that of iRacing, which weights recent races more than older ones trying to reflect a driver’s form.
– V is a factor used to calibrate the speed (amount) at which ratings change. It is not relevant for this article.
– (EA-RA) is the difference between the expected result for A (EA) and the actual result (RA). Better explained with an example.
Imagine Driver A and B, with the exact same ability, racing each other. Both will have the same chance to win a race, each will have a 50% chance. The expected result for each driver is (EA or EB) is 0.5 (50%). When A wins a race, its actual result (RA or RB) is 100% victory, or 1 for similarity. The actual result for B is 0% victory, or 0.
The rating calculations become:
Driver A: GP1 = GP0 + W*V*(EA-RA) = GP0 + E*V*(1–0.5) >>>> A positive change
Driver B: GP1 = GP0 + W*V*(EB-RB) = GP0 + E*V*(0–0.5) >>>> A negative change
In words, the winner’s rating will increase after the race whereas the loser’s rating will decrease.
Imagine that Driver A is twice as good as B. We can expect A to win twice as many races as B. The expected result for A is 66% victory, or 0.66. B has a 33% chance of victory, or 0.33.
In this scenario, the ratings become:
Driver A: GP1 = GP0 + E*V*(eR-aR) = GP0 + E*V*(1–0.66) >>>> A positive change, but smaller than above
Driver B: GP1 = GP0 + E*V*(eR-aR) = GP0 + E*V*(0–0.33) >>>> A negative change, but smaller than above
In words, the higher the rating difference before the race, the smaller the rating variation post-race if the actual result coincides with the expected result.
More math
Better minds than me have spent time elaborating formulas to represent the expected results.
They are (image copy/pasted )